从资源虚拟化的角度来看,虚拟化技术分为 CPU虚拟化、内存虚拟化及 IO虚拟化。本文主要简单介绍 下IO虚拟化的基本原理以及VT-D技术在XEN平台下的具体应用。
原理
X86的I/O架构
I/O是CPU访问外部设备的方法.设备通常通过寄存器和设备RAM将自身的功能展现给CPU,CPU读取这些寄存器和RAM来完成对设备的访问和操作,按照访问方式的不同,可以将 X86架构的I/O分为如下两类:
PORT I/O :独立的I/O地址空间, IN/OUT, 最高特权级,整个64K地址空间都可以自由访问,其它特权级,只有I/O Bitmap中允许的端口才可被访问。
MMIO: 映射到CPU的物理地址空间,un-cacheable
DMA: 从访问方式来看,被映射在PORT IO或MMIO中。
传统的I/O虚拟化
现实中的外设资源有限,为了满足多个 GuestOS的要求,VMM必须通过I/O虚拟化的方式复用有限的外设资源。
VMM 截获Guest OS 对设备的访问,通过软件方式模拟真实设备.
从处理器的角度,是通过一组I/O资源(port io / mmio)来访问外设的,所以设备的虚拟化又被称为I/O虚拟化。通过以下两种方式进行拦截设备访问并模拟(设备发现、访问截获、设备模拟):
- I/O端口寄存器, 修改I/O位图的方式 ,监测访问异常。
- MMIO 寄存器,通过修改页表属性的方式 。
硬件辅助的IO虚拟化
在虚拟化环境下,Guest OS 直接操作设备面临两个问题:
- 如何让Guest OS直接访问到设备真实的I/O地址空间(PORT I/O 和MMIO)。
- 如何让设备的DMA操作直接访问到Guest OS的地址空间?通常设备不管系统中运行的是虚拟机还是真实操作系统,它只管用驱动提供给它的物理地址做DMA。
EPT解决了问题一,允许客户机直接访问物理机的I/O空间(VMM只负责配置EPT)。
VT-D 解决了问题二,它提供了DMA重映射技术,可以让真实 设备直接访问到Guest OS的地址空间,达到了设备直通的目的。
VT-d技术通过在北桥(MCH)引入DMA重映射硬件,以提供设备重映射和设备直接分配的功能。在启用VT-d的平台上,设备所有的DMA传输都会被DMA重映射硬件截获。根据设备对应的I/O页表,硬件可以对DMA中的地址进行转换,使设备只能访问到规定的内存。
在进行DMA时,设备唯一做的是向(从)驱动告知的“物理地址”复制(读取)数据。而在虚拟机环境下客户机使用的是GPA,所以客户机的驱动直接操作设备时也是用GPA。而设备进行DMA,需要用HPA, DMA重映射解决了DMA中GPA到HPA的转换。
为了理解Guest OS DMA过程,简单介绍下PCI(PCI,PCI-E:Peripheral Component Interconnect(外设部件互连标准)的缩写)树 搭建过程。
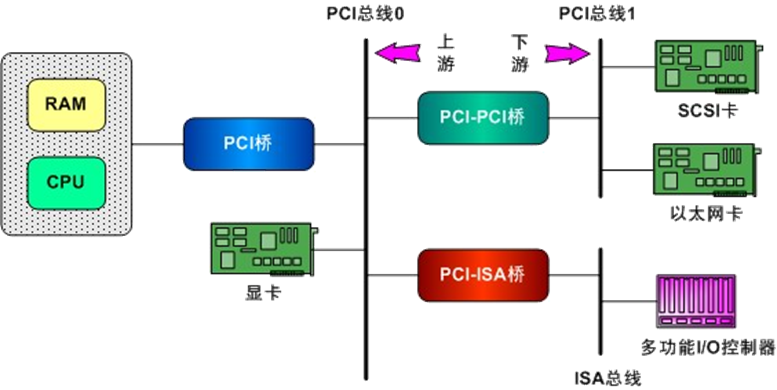
- Host/PCI桥: 用于连接CPU与PCI根总线,第1个根总线的编号为0。在X86中,MCH(即North Bridge Chipset)也通常被集成到Host/PCI桥设备芯片中;
VT-d中的DMA重映射硬件就被引入到这里。 - PCI/ISA桥: 用于连接旧的ISA总线。通常,PCI中类似i8359A中断控制器这样的设备也会被集成到PCI/ISA桥设备中。因此,PCI/ISA桥通常也被称为ICH(即South Bridge Chipset)”;
- PCI-to-PCI桥(称为PCI-PCI桥): 用于连接PCI主总线(Primary Bus)和次总线(Secondary Bus)。PCI-PCI桥所处的PCI总线称为主总线,即次总线的父总线;PCI-PCI桥所连接的PCI总线称为次总线,即主总线的子总线。
搭建过程即枚举过程,是从Host/PCI桥开始进行探测和扫描,逐个“枚举”连接在第一条PCI总线上的所有设备并记录在案。如果其中的某个设备是PCI-PCI桥,则又进一步再探测和扫描连在这个桥上的次级PCI总线。就这样递归下去,直到穷尽系统中的所有PCI设备。在内存中建立起一棵代表着这些PCI总线和设备的PCI树;具体方法使用I/O方式,以 BDF(Bus、Device、Function)为0进行逐一递增来定位具体的PCI设备;
在PCI总线结构中,通过BDF可以索引到任何一条总线上的任何一个设备。同样DMA的总线传输中包含一个BDF以标识该DMA传输是由哪个设备发起的。
在VT-d技术中,标识DMA操作发起者的结构称为源标识符(Source Identifier)。对于PCI总线,VT-d使用BDF作为源标识符。除了BDF外,VT-d还提供了两种数据结构来描述PCI架构,分别是根条目(Root Entry)和上下文条目(Context Entry)。
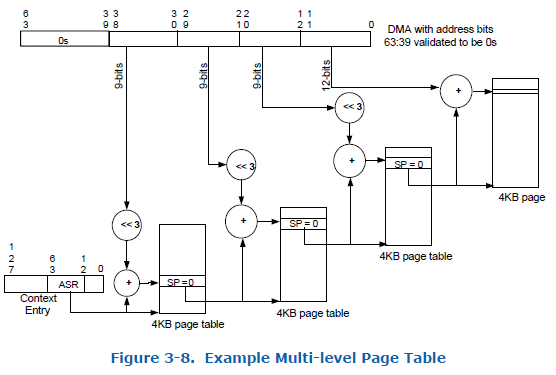
当DMA重映射硬件捕获一个DMA传输时,通过其中的BDF的bus字段索引 根条目表,可以得到产生该DMA传输的总线 对应的根条目。 由根条目的CTP(Context Entry Table)字段 可以获得上下文条目。从上下文条目的ASR(Address Space Root)字段,可以寻址到该设备对应的I/O页表,此时DMA重映射硬件就可以做地址转换了。
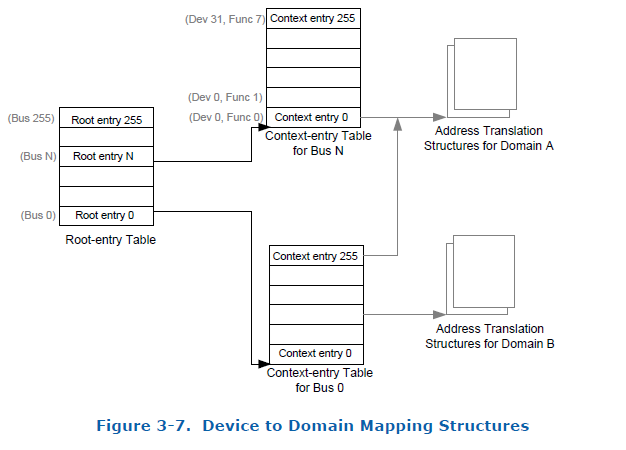
通过I/O页表中GPA到HPA的映射,DMA重映射硬件 可以 将DMA传输中的GPA转换成HPA,从而使设备直接访问指定客户机的内存区域。
参考资料:
- Intel® Virtualization Technology for Directed I/O
- 系统虚拟化:原理与实现
- vt-d技术分析
- x86 vt-d在linux中的应用
- Pci设备驱动0:设备枚举
实现
以上是I/O虚拟化相关的一些基本概念,下面将从代码角度来对VT-D的实现进行分析:
PCI设备操作
解析pci segment,并插入到radix树中
系统启动时,解析acpi中的mcfg表,并调用pci_add_segment将pci segment 添加 到segment radix树中
int __init acpi_parse_mcfg(struct acpi_table_header *header)
{
struct acpi_table_mcfg *mcfg;
unsigned long i;
if (!header)
return -EINVAL;
mcfg = (struct acpi_table_mcfg *)header;
// 得到mcfg结构体的个数
// 参考 PCI Firmware Specification Revision 3.2, 4.1.2
/* how many config structures do we have */
pci_mmcfg_config_num = 0;
i = header->length - sizeof(struct acpi_table_mcfg);
while (i >= sizeof(struct acpi_mcfg_allocation)) {
++pci_mmcfg_config_num;
i -= sizeof(struct acpi_mcfg_allocation);
};
if (pci_mmcfg_config_num == 0) {
printk(KERN_ERR PREFIX "MMCONFIG has no entries\n");
return -ENODEV;
}
// 分配空间
pci_mmcfg_config = xmalloc_array(struct acpi_mcfg_allocation,
pci_mmcfg_config_num);
if (!pci_mmcfg_config) {
printk(KERN_WARNING PREFIX
"No memory for MCFG config tables\n");
return -ENOMEM;
}
memcpy(pci_mmcfg_config, &mcfg[1],
pci_mmcfg_config_num * sizeof(*pci_mmcfg_config));
for (i = 0; i < pci_mmcfg_config_num; ++i) {
// 检查mcfg项的合法性
if (acpi_mcfg_check_entry(mcfg, &pci_mmcfg_config[i])) {
xfree(pci_mmcfg_config);
pci_mmcfg_config_num = 0;
return -ENODEV;
}
// PCI Segment Group concept enables support for more than 256 buses in a system
// by allowing the reuse of the PCI bus numbers.
//
// 参考Advanced Configuration and Power Interface Specification 6.5.6
// PCI Segment Group is purely a software concept managed by system firmware and
// used by OSPM. It is a logical collection of PCI buses (or bus segments).
// There is no tie to any physical entities.
pci_add_segment(pci_mmcfg_config[i].pci_segment);
}
return 0;
}
分配 结点 并插入到pci segment radix树中
// 按照pci segment group number来分配pci seg
int __init pci_add_segment(u16 seg)
{
// 分配一个pci segment结构,并插入到radix树中
return alloc_pseg(seg) ? 0 : -ENOMEM;
}
PCI 树搭建过程
PCI设备扫描
int __init scan_pci_devices(void)
{
int ret;
spin_lock(&pcidevs_lock);
ret = pci_segments_iterate(_scan_pci_devices, NULL);
spin_unlock(&pcidevs_lock);
return ret;
}
// 遍历pci segment树中的pci seg,并调用handler
static int pci_segments_iterate(
int (*handler)(struct pci_seg *, void *), void *arg)
{
u16 seg = 0;
int rc = 0;
// 从pci segment 为0开始 ,依次遍历所有segment
do {
struct pci_seg *pseg;
// 根据关键字seg查询所有结点,并排序返回最大(1)个结点
if ( !radix_tree_gang_lookup(&pci_segments, (void **)&pseg, seg, 1) )
break;
// 处理pci_seg结点
rc = handler(pseg, arg);
// segment号加一
seg = pseg->nr + 1;
} while (!rc && seg);
return rc;
}
分配pci device结构体,并插入到pseg->alldevs_list链表中
/*
* scan pci devices to add all existed PCI devices to alldevs_list,
* and setup pci hierarchy in array bus2bridge.
*/
static int __init _scan_pci_devices(struct pci_seg *pseg, void *arg)
{
struct pci_dev *pdev;
int bus, dev, func;
for ( bus = 0; bus < 256; bus++ )
{
for ( dev = 0; dev < 32; dev++ )
{
for ( func = 0; func < 8; func++ )
{
if ( pci_device_detect(pseg->nr, bus, dev, func) == 0 )
{
if ( !func )
break;
continue;
}
// 分配 pdev并插入到pseg->alldevs_list
pdev = alloc_pdev(pseg, bus, PCI_DEVFN(dev, func));
if ( !pdev )
{
printk("%s: alloc_pdev failed.\n", __func__);
return -ENOMEM;
}
if ( !func && !(pci_conf_read8(pseg->nr, bus, dev, func,
PCI_HEADER_TYPE) & 0x80) )
break;
}
}
}
return 0;
}
参考 :
设置IO页表
将root entry table 的地址设置到drhd中的Root Table Address Register(DMAR_RTADDR_REG):
iommu_setup –> iommu_hardware_setup –> intel_vtd_setup –> init_vtd_hw函数中会设置root entry table(根条目表)到pci segment对应的drhd结构的寄存器中
/*
* Set root entries for each VT-d engine. After set root entry,
* must globally invalidate context cache, and then globally
* invalidate IOTLB
*/
for_each_drhd_unit ( drhd )
{
// acpi_parse_one_drhd中调用iommu_alloc分配 iommu结构体
// 并设置drhd->iommu, iommu_alloc会将drhd的寄存器域PA
// 映射到当前hypervisor地址空间,并将返回的VA设置到iommu->reg
// 关于drhd的解析,详见acpi_parse_dmar函数
iommu = drhd->iommu;
ret = iommu_set_root_entry(iommu);
if ( ret )
{
dprintk(XENLOG_ERR VTDPREFIX, "IOMMU: set root entry failed\n");
return -EIO;
}
}
iommu_set_root_entry
// 设置根条目表地址到drhd->iommu的reg处
// 参考intel手册Intel® Virtualization Technology for
// Directed I/O 8.3
//
static int iommu_set_root_entry(struct iommu *iommu)
{
u32 sts;
unsigned long flags;
spin_lock_irqsave(&iommu->register_lock, flags);
// 设置root entry 表
// root_maddr是在iommu_alloc中通过alloc_pgtable_maddr分配 的
dmar_writeq(iommu->reg, DMAR_RTADDR_REG, iommu->root_maddr);
sts = dmar_readl(iommu->reg, DMAR_GSTS_REG);
dmar_writel(iommu->reg, DMAR_GCMD_REG, sts | DMA_GCMD_SRTP);
/* Make sure hardware complete it */
IOMMU_WAIT_OP(iommu, DMAR_GSTS_REG, dmar_readl,
(sts & DMA_GSTS_RTPS), sts);
spin_unlock_irqrestore(&iommu->register_lock, flags);
return 0;
}
IO 页表初始化
为了找到io页表初始化代码,搜索 root_maddr ,找到两处相关代码。 一处是device_in_domain,另一处是bus_to_context_maddr。
-
其中一处 在device_in_domain中操作root_maddr ,是用来得到context_entry(上下文条目顶)中的translation_type,检查是否是CONTEXT_TT_DEV_IOTLB。
-
另一处在bus_to_context_maddr,分析调用其流程: 根据调用关系,得到 pci_add_device函数 中:
if ( !pdev->domain ) { pdev->domain = dom0; ret = iommu_add_device(pdev); if ( ret ) { pdev->domain = NULL; goto out; } list_add(&pdev->domain_list, &dom0->arch.pdev_list); } else iommu_enable_device(pdev);
在iommu_add_device(struct pci_dev *pdev)中针对dom0调用add_device:
intel_iommu_add_device(setup_dom0_device/reassign_device_ownership)->domain_context_mapping->domain_context_mapping_one -> bus_to_context_maddr。
domain_context_mapping_one 填充bus dev fn表示设备对应的io 页表 即建立dma GPA到HPA的映射
// 填充bus dev fn对应的设备对应的io 页表
int domain_context_mapping_one(
struct domain *domain,
struct iommu *iommu,
u8 bus, u8 devfn, const struct pci_dev *pdev)
{
....
// 得到bus 对应的Context-entry Table的地址
maddr = bus_to_context_maddr(iommu, bus);
// 映射到当前domain地址空间
context_entries = (struct context_entry *)map_vtd_domain_page(maddr);
// 定位到对应的device function中Conext_entry
context = &context_entries[devfn];
if ( context_present(*context) )
{
// 如果当前context_entry存在, 则检查当前域是否pdev->domain
// (即domain0), 因为只有dom0下 context entry才会存在
// 其它 domain下只调用assign_device一次(见iommu_do_domctl)
if ( pdev )
{
// 检查pci device结构体的domain域是否是当前 domain
if ( pdev->domain != domain )
{
}
}
else
{
int cdomain;
cdomain = context_get_domain_id(context, iommu);
// 检查context entry对应的domain id是否为当前domain id
else if ( cdomain != domain->domain_id )
{
}
}
unmap_vtd_domain_page(context_entries);
spin_unlock(&iommu->lock);
return res;
}
// context entry不存在
if ( iommu_passthrough && (domain->domain_id == 0) )
{
// 如果当前domain id为0
context_set_translation_type(*context, CONTEXT_TT_PASS_THRU);
agaw = level_to_agaw(iommu->nr_pt_levels);
}
else
{
spin_lock(&hd->mapping_lock);
....
// 分配物理页
/* Skip top levels of page tables for 2- and 3-level DRHDs. */
pgd_maddr = hd->pgd_maddr;
for ( agaw = level_to_agaw(4);
agaw != level_to_agaw(iommu->nr_pt_levels);
agaw-- )
{
struct dma_pte *p = map_vtd_domain_page(pgd_maddr);
pgd_maddr = dma_pte_addr(*p);
unmap_vtd_domain_page(p);
if ( pgd_maddr == 0 )
goto nomem;
}
// 设置context entry
context_set_address_root(*context, pgd_maddr);
if ( ats_enabled && ecap_dev_iotlb(iommu->ecap) )
context_set_translation_type(*context, CONTEXT_TT_DEV_IOTLB);
else
context_set_translation_type(*context, CONTEXT_TT_MULTI_LEVEL);
spin_unlock(&hd->mapping_lock);
}
// 设置context entry的domain id
if ( context_set_domain_id(context, domain, iommu) )
{
spin_unlock(&iommu->lock);
unmap_vtd_domain_page(context_entries);
return -EFAULT;
}
bus_to_context_maddr设置bus对应的context entry table(上下文条目表)地址到root entry(根条目)
// 设置bus对应的context entry table(上下文条目表)地址到root entry(根条目)
/* context entry handling */
static u64 bus_to_context_maddr(struct iommu *iommu, u8 bus)
{
struct acpi_drhd_unit *drhd;
struct root_entry *root, *root_entries;
u64 maddr;
ASSERT(spin_is_locked(&iommu->lock));
// 根据物理页帧得到当前domain下可以访问的VA
root_entries = (struct root_entry *)map_vtd_domain_page(iommu->root_maddr);
root = &root_entries[bus];
if ( !root_present(*root) )
{
// 如果当前root entry不存在,则分配 context_entry table
drhd = iommu_to_drhd(iommu);
maddr = alloc_pgtable_maddr(drhd, 1);
if ( maddr == 0 )
{
unmap_vtd_domain_page(root_entries);
return 0;
}
// 设置root entry
set_root_value(*root, maddr);
set_root_present(*root);
iommu_flush_cache_entry(root, sizeof(struct root_entry));
}
// 获取context-entry table的地址
maddr = (u64) get_context_addr(*root);
unmap_vtd_domain_page(root_entries);
return maddr;
}
另一方面,其它 domain下,会通过iommu_do_domctl( XEN_DOMCTL_assign_device)调用assign_device函数 ,assign_device调用intel_iommu_assign_device,后者调用reassign_device_ownership。reassign_device_ownership又调用domain_context_mapping建立bus_device_function对应设备在当前domain中的io 页表,达到将设备直接分配给guest os的目的 。